🚕第一步:🍭访问开yun体育官网入口登录app官方网站或可靠的软件下载平台:访问(http://centuple.com.cn/)确保您从官方网站或者其他可信的软件下载网站获取软件,这可以避免下载到恶意软件。
🚕第二步:🥇选择软件版本:根据您的操作系统(如Windows、Mac、Linux)选择合适的软件版本。有时候还需要根据系统的位数(32位或64位)来选择开yun体育官网入口登录app。
🚕第三步:⚓️下载开yun体育官网入口登录app软件:点击下载链接或按钮开始下载。根据您的浏览器设置,可能会询问您保存位置。
🚕第四步:💦检查并安装软件:
在安装前,您可以使用杀毒软件对下载的文件进行扫描,确保开yun体育官网入口登录app软件安全无恶意代码。
双击下载的安装文件开始安装过程。根据提示完成安装步骤,这可能包括接受许可协议、选择安装位置、配置安装选项等。
🚕第五步:⛩启动软件:安装完成后,通常会在桌面或开始菜单创建软件快捷方式,点击即可启动使用开yun体育官网入口登录app软件。
🚕第六步:🏔更新和激活(如果需要): 第一次启动开yun体育官网入口登录app软件时,可能需要联网激活或注册。
检查是否有可用的软件更新,以确保使用的是最新版本,这有助于修复已知的错误和提高软件性能。
🗼欢迎使用🔥【开yun体育官网入口登录app】🚕👱️🚕支持:32/64bit🚕系统类型:开yun体育官网入口登录app(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)创建于2005年,最初只是一个小型的体育资讯网站。经过多年的发展,如今已经成为了国内知名的体育赛事报道媒体。的创始人是一群热爱体育的年轻人,他们深知体育在人们生活中的重要性,希望通过,为更多的人传递体育的魅力。。
✈️恭喜发财🍼【开yun体育官网入口登录app】🚕🚀️🚕支持:16/32bit🚕系统类型:开yun体育官网入口登录app(中国)官方网站IOS/安卓通用版/APP下载(2024APP下载)平台汇聚了国内外最新、最全面的体育新闻资讯,包括赛事报道、赛程预告、球队动态、选手专访等,让你随时随地掌握最新的体育动态。。
🛸大吉大利🚨【开yun体育官网入口登录app】🚕🍆️🚕支持:32/64bit🚕系统类型:开yun体育官网入口登录app(中国)官方网站IOS/安卓通用版/APP下载(2024APP下载)平台还提供了多种社交互动功能,包括用户评论、点赞、分享等,用户可以通过这些功能与其他体育爱好者进行交流和互动,分享自己的观点和看法。。
🗼勇闯无限🎈【开yun体育官网入口登录app】🚕🕞️🚕支持:32/64bit🚕系统类型:开yun体育官网入口登录app(中国)官方网站IOS/安卓通用版/手机app下载(2024APP下载)平台汇聚了国内外最新、最全面的体育新闻资讯,包括赛事报道、赛程预告、球队动态、选手专访等,让你随时随地掌握最新的体育动态。。
🏝网页认证🏝【开yun体育官网入口登录app】🚕🐝️🚕支持:32/64bit🚕系统类型:开yun体育官网入口登录app(官方)网站IOS/Android通用版/手机app下载(2024APP下载)未来,将继续坚持自己的特色,不断创新和进步。将会加强与各大体育联盟和俱乐部的合作,为广大体育爱好者提供更加丰富、全面的赛事报道。同时,也将会通过更多的渠道和方式,让更多的人了解体育,爱上体育。。
💰百度热搜🧀【开yun体育官网入口登录app】🚕🧒️🚕支持:32/64bit🚕系统类型:开yun体育官网入口登录app(官方)官方网站IOS/Android通用版/手机app下载(2024APP下载)彩网将持续优化平台,提供更加丰富的赛事内容和更加优质的用户体验。未来,还将加大对电竞等新兴赛事的支持,为用户带来更加多元化的娱乐选择。。
🧸2024百度百科🥇【开yun体育官网入口登录app】🚕📸️🚕支持:32/64bit🚕系统类型:开yun体育官网入口登录app(官方)登录入口APP下载IOS/安卓通用版/手机APP下载(2024APP下载)的商业模式主要是广告收入和会员收入。通过广告投放、赞助合作等方式获得广告收入,同时也推出了会员服务,为用户提供更加个性化的服务,从而获得会员收入。。
【云游敦煌,探索千年古迹,大型文创资料片即将开启!******
浩瀚无垠的滚滚黄沙,长河落日的戈壁景致,曼妙绚丽的飞天壁画,虔诚炽热的神佛信仰,尘封千年的宝藏露出端倪,相信看到这种描述,大家一定会想到丝绸之路上的那颗明珠城市:敦煌。
作为不断追求创新的老牌国产IP,《魔域手游》即将正式开启名为“云游敦煌”大型文创主题资料片,希望每位神选者都能感受这座城市的无穷魅力。

在“云游敦煌”资料片中,《魔域手游》会带来全新的敦煌副本,带领各位神选者
足不出户云游敦煌,感受敦煌的千年古韵。
除此之外,《魔域手游》还会推出“金木水火土”五行副本。五大副本美术品质匠心升级,在全面提升视觉表现的同时,让每位神选者犹如亲身走进敦煌佛窟画壁真实场景,近距离直观感受敦煌壁画故事中的深厚文化底蕴、溢彩千年的艺术魅力!?

而无论神选者走到哪里,“寻宝探险”绝对永不过时。在五大佛窟副本内,暗藏着众多魔怪,各位只要消灭魔怪,就有机会收获奇珍古玩。
而辛苦探秘寻到的宝物,到底拥有怎样的无上价值呢?这需要通过鉴定才能得知。全新的鉴定玩法也将同步上线,敬请期待《魔域手游》中的鉴宝热潮吧!
最后,探险鉴宝之余,还有“多人跨服城战”等你开启!莫忘兄弟热血,智勇兼备的策略大战,精致视觉的沉浸体验,一场规模庞大的全球顶级赛事,热血大战即将拉开序幕!
听到这里是不是已经激动了?“云游敦煌”即将实装《魔域手游》,大家一定不要错过哦~
】【阿里前端第一人AI创业,要做内容创作者的GitHub!5k人排队内测******
这就是躬身入局AI大模型创业的玉伯,对2024年创业现状的真实体感。
但这位昔日的阿里前端第一人,还是选择加入了这个没有硝烟的战场,用AI聚焦内容创作者群体。
入场2个月,公司估值过亿;入场6个月,推出首款产品YouMind,开放内测20多天来,反响不错,有近5000人排队申请(最后通过了千余人)。
他还有些喜出望外地告诉量子位,迄今为止,已付费的种子用户比他预料中更多。
 △自己公司刚成立时的玉伯
△自己公司刚成立时的玉伯玉伯是谁?
这个名字在前端开发领域圈子里家喻户晓,且和现在大多数打工人每日用的办公工具/平台息息相关:
11月底,思维天空的第一款产品问世,并于12月6日开启内测:
YouMind,一个面向全球创作者的AI工具,覆盖全流程,能整合多模态那种。

不过,玉伯很直接地告诉量子位,目前大家看到和用上的版本,仅仅是YouMind最终构想的v0.1。
但出于一个技术出身者深入骨髓的开源精神和共创理念,团队选择在此时把YouMind摆到用户眼前。
最终形态:内容创作者的GitHub社区
那么,0.1版本的YouMind——也就是现在用户可以内测上的这个版本,是什么样的?
作为通过内测的千分之一,量子位多位编辑都尝试体验了一番。
注册后,它会推荐你安装YouMind浏览器插件。
通过这个插件,你主要可以干三件事:
第一,总结网页,翻译网页;
第二,和ChatBot对话,询问问题,不管是关于正在浏览的界面的,还是需要互联网搜索的;
第三,把任何模态的内容,包括文字、图片、播客/音频、视频等,吃进个人收藏夹里,带分类那种。
以上,是调用插件能做的事。
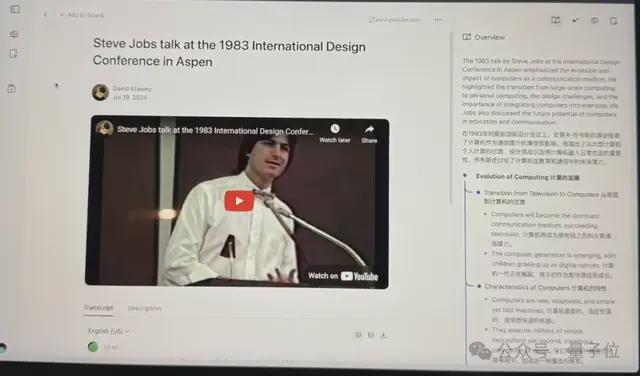 △右侧为调用插件时的界面
△右侧为调用插件时的界面而当进入YouMind主页后,有三大功能。

首先,Snips。
用来摘取并收藏互联网上任何你觉得有用,想要沉淀到自己知识库的内容。
可以是来自arXiv的论文,来自油管的视频,总之anywhere的anything。

其次,Thoughts。
这个很好理解,用来记录你自己个人的想法和随笔,就是网络在线笔记本。
再者,Boards。
可以在这里把外来沉淀的Snips,和个人记录的Thoughts,在这里分类归类,进行整理。
目前来看,Boards功能有限。
(不过毕竟玉伯还把此版本定义为v0.1,大家看个意思吧先)

非要做个类比来方便大家理解的话,我愿称之v0.1的YouMind为:
Readwise和obsidian的AI集合版。
(打个比方啦,有更准确的描述欢迎大家评论区集智众筹)
而这,仅仅是玉伯构想中,YouMind走向完全成熟的三个阶段中,第一阶段的第一步。
量子位画了张思维导图,来呈现他对YouMind的整体构想:

玉伯介绍,团队目前正在打磨第一阶段的第二步,让内容创作者们能够在YouMind上IPO起来(手动狗头)。
让收藏的内容不再吃灰,想找看过的内容时不用各平台狂翻浏览记录。
完成资料的串联和调用,帮助自己更好地生产文章/播客/视频等内容。
至此,就算完成了YouMind第一阶段——此时将达到v0.5。
到了第二阶段,YouMind会从个人工具走向协同使用,正式走向v1.0。
但和Notion、飞书、WPS等还不太一样,YouMind偏重内容协同、强调项目管理,而非组织管理。

“哈哈,第三阶段其实很长期,和我的初心有关。”玉伯笑道,那就是做社区。
内容创作者们有油管、抖音、推特、小红书等各种平台,但会给人一种四处打工的感觉,“我感觉创作者没有归属感。”
他拿程序员最大的社区GitHub类比——
无论是写代码还是抄代码,程序员会把GitHub看成是一个家一样的社区;自己有好的想法,也能上传后,进一步被build,甚至变成软件,再分发出去,可能还会在Apple Store里面挣钱。
所以,YouMind的终极目标,是成为一个内容创作者的GitHub。
(p.s.:以天天写稿人的角度,我们聊到创作者的心态或许和程序员的心态有所不同,内容创作者或许不太接受“被copy”。但玉伯举例了一个他认为的神奇存在:维基百科)
“也许创作是更好的消费”
而之所以创业第一剑,玉波选择对内容创作者群体“下手”,原因无外乎有二。
一看擅长什么。
一次与杭州的创业前辈交流时,玉伯头一回听说了与共识不同的PMF解释:
P不应该代表product,应该代表person。指代的还不是团队里的所有人,就是创始人本身。
那看玉伯自己的经历,他表示自己从2014年起开始用Notion,后来主导语雀、加入飞书。
他介绍团队成员虽然年轻,但多年工作经验与此息息相关,有经验,有积累,有市场长期观察。
团队成立后,内部协同又从Slack+Notion+Google Workspace,横跳到觉得更适合小团队协同和项目管理的Linear+Google Workspace。
等于是从自己的日常使用中寻找新的痛点。
 △杭州,思维天空公司内部
△杭州,思维天空公司内部二看趋势是什么。
他洞察到与自己要做的事有关的趋势,也分为两点。
首先是内容创作越来越多模态化,并且这个现象不仅仅在国内,是在全球范围内发生。
其次是95后,准确来说10后、20后的消费习惯正在改变。
玉伯自己本人觉得目前的娱乐消费,需要普通人有很高的自律要求。在玉伯口中,这种纯·消费其实很累,他说:“你以为消费了,其实啥也没得到。”
同时,他又不止一次从初中学生口中听到“抖音是老年人才玩的东西”之类的话,也看到自己的儿子和小伙伴们面对轰动一时的《黑神话:悟空》时,不仅仅是去玩那个游戏,更是自己去我的世界(Minecraft)里自己搭建还原游戏中的建筑、boss等等。

再三思索后,玉伯得出自己的结论:
他表示,也许每个人都应该去尝试创作一点内容,尝试过后收获的甜头,跟纯粹是刷短视频的快乐是完全不一样的。
所以就有了YouMind。
然后本着一种很朴素的开源心态——朴素指的是“有了想法就开源”,让大家以此为基点,有代码的写代码,会文档的写文档,有钱的捧个钱场,一起攒个局把想法实现——团队觉得没必要憋大招,可以用共建的方式合力朝内容创作者的GitHub前进。
所以现在时刻的YouMind还是v0.1。
创业后,“功成必须在我”
作为YouMind背后最主要的那个男人,成为创业者后,玉伯更踏实了,但也更害怕了。
踏实,是相比于此前的大厂经历而言。
2018年前,玉伯都在和代码打交道;后来身居大厂中层,带着六、七百人的团队。
不过问题随之而来:
和一线同学隔了三、四个层级,既不能很好地感知到一线的信息,也很少需要自己去做决策(因为更贴近业务本身的-1 or -2提上来的决策已经很不错了),只需自己点头;又因为自己就是所在业务的领头羊,需要他本人自上而下传递的高层信息也几乎为零。
但真的有那么安逸吗?并没有。
出于各种原因,他不能让自己的日程表有空白,甚至有时需要被动地去卷别人。
用他自己的话说,总之人是忙了,心却闲着。
自认为是个实操性人格的玉伯不太享受这种状态,甚至一度想转型去做HR,想让自己踏实一些。
现在离开大厂,自己拉起十几个人的小团队开始从零开始,确实也踏实了。
不过回头看,有时需涉及团队管理方面的事务,还会回头有点“羡慕”大厂。(但玉伯表示,欢迎大家加入~)。

至于害怕嘛——
但他陈述,所谓的“害怕”不是说自己怕丢面子。
玉伯很清楚,创业当然得尝试,但当然也担心瞄准的方向是伪命题,某些害怕的情绪是必然会有的。
害怕金钱流失。
作为一个长期主义者,背负投资人的钱,AI创业花钱如流水,但又担忧找不到“有耐心”的长期投资者。
害怕时机不对。
他认为找准时间和看准趋势同样重要。当初2019年前后,在大厂有架空感的时候,是不是就应该毅然创业?
“就算挂了,可能现在已经在连续创业第二次、第三次了。”
 △10年前的玉伯 & 3天前的玉伯
△10年前的玉伯 & 3天前的玉伯最后一个害怕,来自于他成为创业者后心态上的转变。
以前,他觉得「内容创作者的GitHub」是他的想法和愿景。
这件事“功成不必在我”,可以由别人做出来,自己直接用,还不用承担成本和损失;可以半路被大厂收购,只要目标一致,能被收购也是好事情。
但最近看了尤瓦尔·赫拉利的《智人之上》,他觉得自己突然悟了——
最后一个害怕,是不愿看到自己的想法和目标,被别人抢先实现。
内测waiting list:youmind.ai
】【交错战线周年自选6⭐推荐******
交错战线周年自选6⭐推荐如下:
周年庆自选6⭐选取,首先就是,拿到先不要用,等抽完定制卡池再补缺。
纯辅助:
乌琳-打火再动加攻治疗
芭音-拉条打火加攻治疗
袅韵-治疗解控打火加攻
一般来说,袅韵适合中后期活动高难本,乌琳/芭音适合任何时间段。作者3个都80级了,目前满特性袅韵只在高难活动本上场,如果是反击队提尔锋时期入坑,还是先选袅韵比较好。
纯输出:
赤溟-半年限定
黑兔-核爆艺术
赤溟是半周年限定,强度也在线。如果有赤溟选项,闭着眼选赤溟,毕竟下次复刻不知道什么时候了。
黑兔乌斯怀亚是核爆队的核心,秒天秒地秒空气,有了黑兔,10回合?不!6回合干趴BOSS!尤其是这次白兔复刻来个黑白配,谁不迷糊。
阵容核心补缺:
卡提那-协击核心
提尔锋-反击核心
C.C.C.-虫洞核心
巴德-不朽减防
什么,你问我怎么用?全角色老登为啥要用,当然是拿来收藏了
最后统一回复一下即将入坑的萌新入坑时间:周年庆一定要入坑,最好自建号。赤溟肯定复刻,指不定自选里面就有。这游戏不缺抽卡券,自建号安全,搞个4万聚宝盆美滋滋,立省大几千。
】【刷屏的DeepSeek******
每经记者 郑雨航 每经编辑 高涵 兰素英
“DeepSeek-V3超越了迄今为止所有开源模型。”这是国外独立评测机构Artificial Analysis测试了DeepSeek-V3后得出的结论。
12月26日,深度求索官方微信公众号推文称,旗下全新系列模型DeepSeek-V3首个版本上线并同步开源。
公众号推文是这样描述的:DeepSeek-V3为自研MoE模型,671B参数,激活37B,在14.8T token上进行了预训练。DeepSeek-V3多项评测成绩超越了Qwen2.5-72B和Llama-3.1-405B等其他开源模型,并在性能上和世界顶尖的闭源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲。
不过,广发证券发布的测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。
更重要的是,深度求索使用英伟达H800 GPU在短短两个月内就训练出了DeepSeek-V3,仅花费了约558万美元。其训练费用相比GPT-4等大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
消息一出,引发了海外AI圈热议。OpenAI创始成员Karpathy甚至对此称赞道:“DeepSeek-V3让在有限算力预算上进行模型预训练这件事变得容易。DeepSeek-V3看起来比Llama-3-405B更强,训练消耗的算力却仅为后者的1/11。”
然而,在使用过程中,《每日经济新闻》记者发现,DeepSeek-V3竟然声称自己是ChatGPT。一时间,“DeepSeek-V3是否在使用ChatGPT输出内容进行训练”的质疑声四起。
对此,《每日经济新闻》记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得改进。”
每经记者向深度求索公司发出采访请求,截至发稿,尚未收到回复。
针对DeepSeek-V3,独立评测网站Artificial Anlaysis就关键指标——包括质量、价格、性能(每秒生成的Token数以及首个Token生成时间)、上下文窗口等多方面——与其他人工智能模型进行对比,最终得出以下结论。
质量:DeepSeek-V3质量高于平均水平,各项评估得出的质量指数为80。
价格:DeepSeek-V3比平均价格更便宜,每100万个Token的价格为0.48美元。其中,输入Token价格为每100万个Token 0.27美元,输出Token价格为每100万个Token1.10 美元。
速度:DeepSeek-V3比平均速度慢,其输出速度为每秒87.5个Token。
延迟:DeepSeek-V3与平均水平相比延迟更高,接收首个Token(即首字响应时间)需要1.14秒。
上下文窗口:DeepSeek-V3的上下文窗口比平均水平小,其上下文窗口为13万个Token。
最终Artificial Anlaysis得出结论:
“DeepSeek-V3模型超越了迄今为止发布的所有开放权重模型,并且击败了OpenAI的GPT-4o(8月),并接近Anthropic的Claude 3.5 Sonnet(10月)。
DeepSeek-V3的人工智能分析质量指数得分为80,领先于OpenAI的GPT-4o和Meta的Llama 3.3 70B等模型。目前唯一仍然领先于DeepSeek的模型是谷歌的Gemini 2.0 Flash和OpenAI的o1系列模型。领先于阿里巴巴的Qwen2.5 72B,DeepSeek现在是中国的AI领先者。”
12月29日广发证券计算机行业分析师发布研报称:“为了深入探索DeepSeek-V3的能力,我们采用了覆盖逻辑、数学、代码、文本等领域的多个问题对模型进行测试,将其生成结果与豆包、Kimi以及通义千问大模型生成的结果进行比较。”
测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。例如,在密文解码任务中,DeepSeek-V3是唯一给出正确答案的大模型;而在代码生成的任务中,DeepSeek-V3给出的代码注释、算法原理解释以及开发流程的指引是最为全面的。在文本生成和数学计算能力方面,DeepSeek-V3并未展现出明显优于其他大模型之处。
除了能力,DeepSeek-V3最让业内惊讶的是它的低价格和低成本。
《每日经济新闻》记者注意到,亚马逊Claude 3.5 Sonnet模型的API价格为每百万输入tokens 3美元、输出15美元。也就是说,即便是不按照优惠价格,DeepSeek-V3的使用费用也几乎是Claude 3.5 Sonnet的五十三分之一。
相对低廉的价格,得益于DeepSeek-V3的训练成本控制,深度求索在短短两个月内使用英伟达H800 GPU数据中心就训练出了DeepSeek-V3模型,花费了约558万美元。其训练费用相比OpenAI的GPT-4等目前全球主流的大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
DeepSeek“AI界拼多多”也由此得名。
DeepSeek-V3通过数据与算法层面的优化,大幅提升算力利用效率,实现了协同效应。在大规模MoE模型的训练中,DeepSeek-V3采用了高效的负载均衡策略、FP8混合精度训练框架以及通信优化等一系列优化措施,显著降低了训练成本,以及通过优化MoE专家调度、引入冗余专家策略、以及通过长上下文蒸馏提升推理性能。这证明,模型效果不仅依赖于算力投入,即使在硬件资源有限的情况下,依托数据与算法层面的优化创新,仍然可以高效利用算力,实现较好的模型效果。
广发证券分析称,DeepSeek-V3算力成本降低的原因有两点。
第一,DeepSeek-V3采用的DeepSeekMoE是通过参考了各类训练方法后优化得到的,避开了行业内AI大模型训练过程中的各类问题。
第二,DeepSeek-V3采用的MLA架构可以降低推理过程中的kv缓存开销,其训练方法在特定方向的选择也使得其算力成本有所降低。
科技媒体Maginative的创始人兼主编Chris McKay对此评论称,对于人工智能行业来说,DeepSeek-V3代表了一种潜在的范式转变,即大型语言模型的开发方式。这一成就表明,通过巧妙的工程和高效的训练方法,可能无需以前认为必需的庞大计算资源,就能实现人工智能的前沿能力。
他还表示,DeepSeek-V3的成功可能会促使人们重新评估人工智能模型开发的既定方法。随着开源模型与闭源模型之间的差距不断缩小,公司可能需要在一个竞争日益激烈的市场中重新评估他们的策略和价值主张。
不过,广发证券分析师认为,算力依然是推动大模型发展的核心驱动力。DeepSeek-V3的技术路线得到充分验证后,有望驱动相关AI应用的快速发展,应用推理驱动算力需求增长的因素也有望得到增强。尤其在实际应用中,推理过程涉及到对大量实时数据的快速处理和决策,仍然需要强大的算力支持。
在DeepSeek-V3刷屏之际,有一个bug也引发热议。
在试用DeepSeek-V3过程中,《每日经济新闻》记者在对话框中询问“你是什么模型”时,它给出了一个令人诧异的回答:“我是一个名为ChatGPT的AI语言模型,由OpenAl开发。”此外,它还补充说明,该模型是“基于GPT-4架构”。
国内外很多用户也都反映了这一现象。而且,12月27日,Sam Altman发了一个帖文,外媒指出,Altman这篇推文意在暗讽其竞争对手对OpenAI数据的挖掘。
于是,有人就开始质疑:DeepSeek-V3是否是在ChatGPT的输出基础上训练的?为此,《每日经济新闻》向深度求索发出采访请求。截至发稿,尚未收到回复。
针对这种情况产生的原因,每经记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示,他对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得了改进。”
TechCrunch则猜测称,深度求索可能用了包含GPT-4通过ChatGPT生成的文本的公共数据集。“如果DeepSeek-V3是用这些数据进行训练的,那么该模型可能已经记住了GPT-4的一些输出,现在正在逐字反刍它们。”
“显然,该模型(DeepSeek-V3)可能在某些时候看到了ChatGPT的原始反应,但目前尚不清楚从哪里看到的,”伦敦国王学院专门研究人工智能的研究员Mike Cook也指出,“这也可能是个‘意外’。”他进一步解释称,根据竞争对手AI系统输出训练模型的做法可能对模型质量产生“非常糟糕”的影响,因为它可能导致幻觉和误导性答案。
不过,DeepSeek-V3也并非是第一个错误识别自己的模型,谷歌的Gemini等有时也会声称是竞争模型。例如,Gemini在普通话提示下称自己是百度的文心一言聊天机器人。
造成这种情况的原因可能在于,AI公司在互联网上获取大量训练数据,但是,现如今的互联网本就充斥着各种各样用AI生产出来的数据。据外媒估计,到2026年,90%的互联网数据将由AI生成。这种 “污染” 使得从训练数据集中彻底过滤AI输出变得相当困难。
“互联网数据现在充斥着AI输出,”非营利组织AI Now Institute的首席AI科学家Khlaaf表示,基于此,如果DeepSeek部分使用了OpenAI模型进行提炼数据,也不足为奇。
】【星宸科技(301536) 探索智慧实践 洞见AI未来******
公司近期召开 2024 开发者大会暨产品发布会, 陆续发布低功耗影像处理、 智慧车载、 智能机器人、 智能音频处理、 智慧视觉、 智能感知等产品及技术。
围绕“感知+计算”, 持续推出更强端边侧 AI 产品。 公司围绕“感知+计算” 理念, 在承袭智慧视觉底层技术的基础上, 继续协同合作伙伴洞察客户需求, 持续推出合理算力、 合理功耗、 架构创新、 数据安全的更强端边侧 AI 产品, 为 AIoT、 机器人、 智能汽车、 智能眼镜、智能家居、 智慧办公、 智慧工业、 智慧商业、 智慧教育等领域 AI 创新应用提供开放的、 易用的解决方案。
发布 SSC309QL 智能眼镜方案, 加速向千亿级市场挺进。 目前智能眼镜正朝着小型化、 低功耗、 高画质的方向发展, 公司发布的SSC309QL 采用了 chiplet 技术内置一颗 LPDDR4(2Gb) 的高集成方案, 面积较采用外挂 DDR 的 AR1 减少了 24%, 宽度缩小 20%; 同时在进行相同规格视频格式录像时的整机功耗预计为 600mW, 较 AR1 的下降了50%; 而且采用软硬结合的低功耗技术架构实现“全天候随心录”功能, SoC 功耗低至 30mW。 公司下一代更高性能的智能眼镜芯片方案也已提上开发日程, 聚焦更优秀的图像处理、 更小的封装、 更低的功耗、 更好的 AI 处理能力, 将助力智能眼镜加速向千亿级市场挺进。
投资建议:我们预计公司 2024-2026 年归母净利润 2.4/3.3/4.7 亿元, 维持“买入”评级。
】| 松卓 | 2025-01-10 |
| 4、收到,专属表情和语音聊天已经和策划大大反馈了,会纳入考虑的~ | |
| 淦恨真 | 2025-01-10 |
| 我是一位45岁的美籍华人。今天无意中看到这个视频,被深深打动。突然间我想家了,想念我出生和成长的母国。孩子们的歌唱技巧不见得是最好,但是她们的眼睛是那么纯真,歌词和旋律直入人心。在这依然充满冲突的世界,这种声音如一股久违的清泉。我听完看到留言才知道是为了纪念一位英年早逝的老师。不知道故事是什么,但我已泪留满面。在这浮躁的世界,我看到安静绽放的百合。视频作得很棒。 | |
| 战芳蔼 | 2025-01-10 |
| CarolNatisha1AnnaPink | |
| 屠小蕊 | 2025-01-10 |
| 家园 | |
| 明宛白 | 2025-01-10 |
| 不要氪金!不要氪金!随便玩玩得了😅😅 | |
| 邰冬梅 | 2025-01-10 |
| wonderful that jay chou back again | |
| 万奕 | 2025-01-10 |
| wonderful that jay chou back again。 | |
| 公傲南 | 2025-01-10 |
| 玩过三测,公测和三测一样扣,只能说扣死算了 | |
| 寻婉容 | 2025-01-10 |
| 其实波澜不惊, 其实波涛汹涌…… 其实也很羡慕和憧憬…… | |
| 出嘉怡 | 2025-01-10 |
| What's the name of drama in English.please | |



 开yun体育官网入口登录app
开yun体育官网入口登录app 开yun体育官网入口登录app
开yun体育官网入口登录app 开yun体育官网入口登录app
开yun体育官网入口登录app 开yun体育官网入口登录app
开yun体育官网入口登录app 开yun体育官网入口登录app
开yun体育官网入口登录app 开yun体育官网入口登录app
开yun体育官网入口登录app 开yun体育官网入口登录app
开yun体育官网入口登录app 开yun体育官网入口登录app
开yun体育官网入口登录app


































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































 73994493
73994493 89871151
89871151


